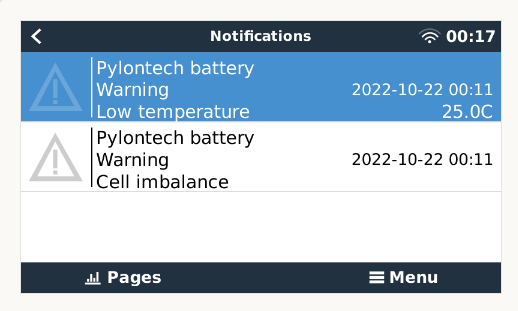
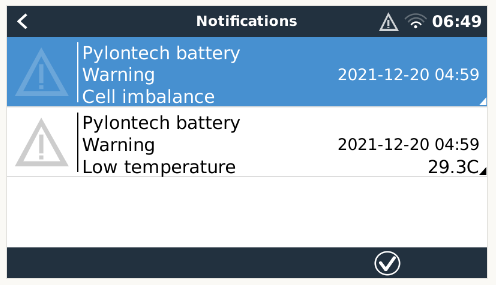
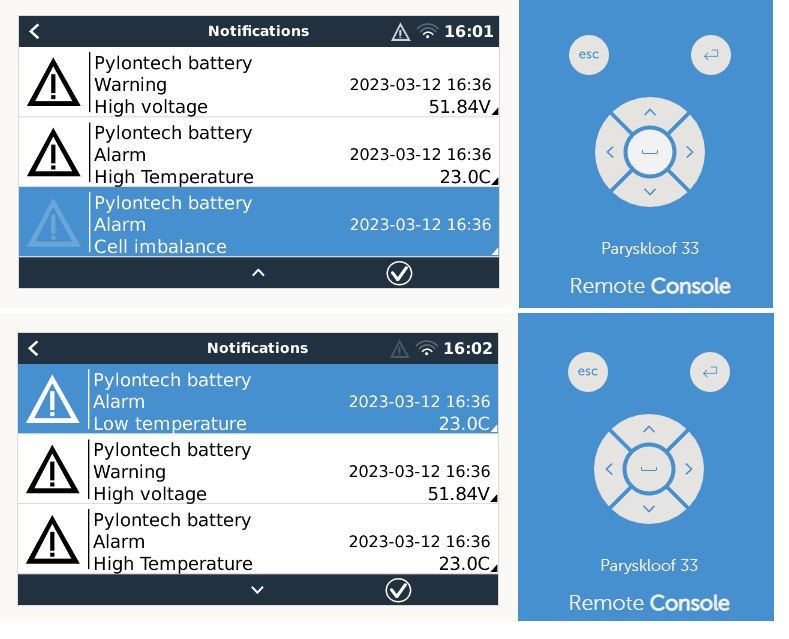
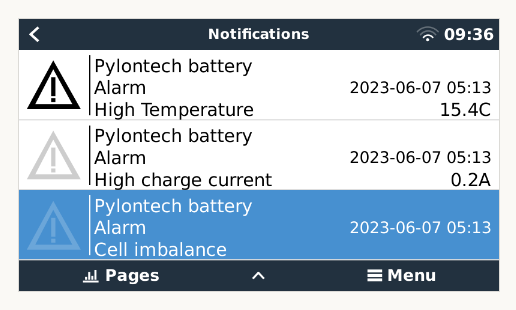
I’m getting strange battery errors reported by the Cerbo on two different sites. Both sites have Pylontech batteries. It happens very intermittently, perhaps once a month. Examples:
It is always a combination of a low temperature and cell imbalance, and both errors clear immediately. I used BatteryView to see if there’s anything in the Pylontech event logs and it comes up empty. As far as I can tell there’s no actual problem on the battery side, which makes me suspect that there’s a communication issue between the batteries and Cerbo. I’ve checked and reseated the cables on both sites, but the errors still pop up from time to time.
I might remember the wrong thing here, but do you have the latest GX version installed?
I vaguely remember reading a release note about this, but it may have been something else. I’ll try finding it again, but try updating the GX for now.
Yes, I’m keeping up to date with the GX releases on both sites. The one site is currently on the 3.0 release candidate and the other on 2.93. The one on 2.93 threw this again two days ago:
There doesn’t seem to be any rhyme or reason to it. It happens at any time of the day and at any charge level.
I’ve also kept the firmware of the batteries at both sites updated to the latest. The one site has US2000C batteries and the other US2000B+.
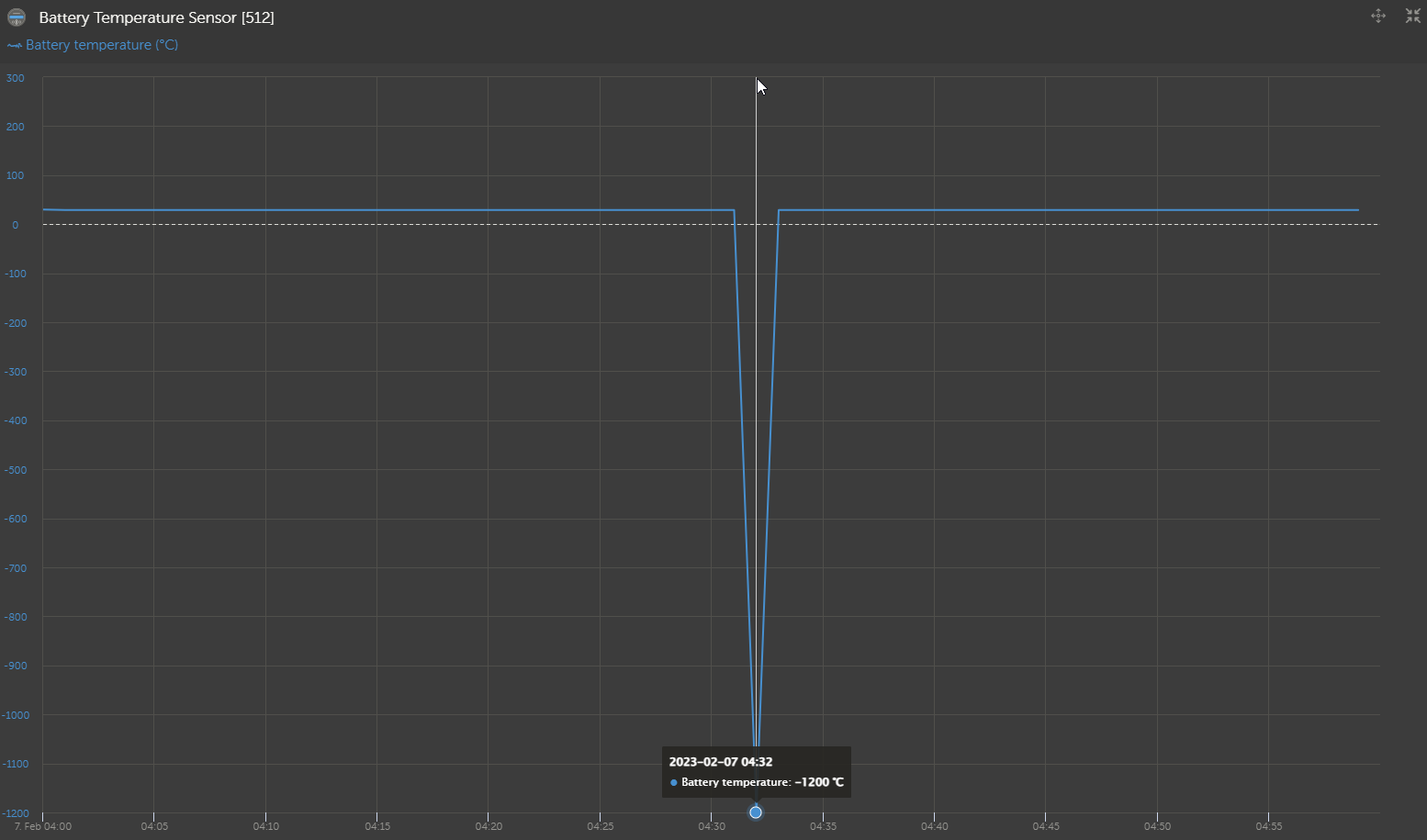
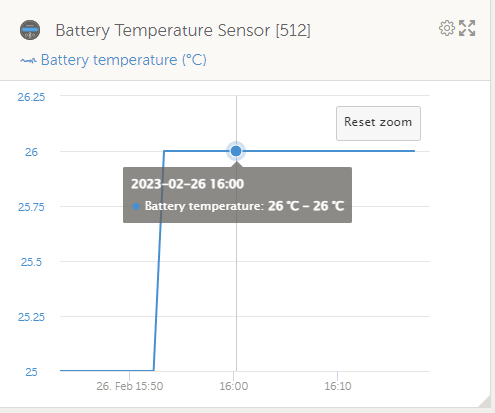
I zoomed in on the time in question, and the temperature was stable over the time of the last warning:
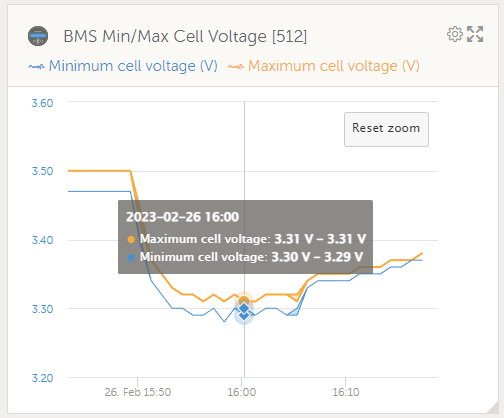
The simultaneous cell imbalance warning is even more curious, since it also happens when the battery is in the flat part of the LFP charge curve and all the cell voltages are within a few mV of each other.
If you’re technically minded, and have the patience to wait for it, you can run:
candump can0 | grep -e '35[9A]'
You may have to use can1 on a Cerbo, depends, I cannot remember, I just try both until one of them works. There is a way to tell candump to do the filtering, but grep is just easier. Then you should see 359, and maybe also 35A if the firmware is new enough (Victron will use 35A if they are both there):
can0 359 [7] 00 00 00 00 01 50 4E
can0 35A [8] AA AA AA 02 00 00 00 00
Explanation. The 50 4E at the end is the ascii letters PN. It’s an old legacy way of detecting the battery. The 01 before it says there is one battery module in the system where I made this demonstration. The 4 x 00 before it indicates that there are no warnings or errors in this system.
Similarly, 0x35A should show a binary pattery that is 101010... if everything is okay, which is why you see the hex digit A repeatedly (because hex A == 1010 in binary). 2 is also 10 in binary. There are a few unsupported alarms in this battery (things it doesn’t monitor), which is why there are a bunch of zero bits in the middle. 0xAAAAAA02 means everything is okay. If you see anything else, there is an alarm or a warning.
The fact that the second half of 0x35A is all zeroes, means this battery will never raise an alarm, only warnings. 00 means “not supported”.
So… capture that into a file, or something, and see if the error on the screen actually corresponds with something on the CAN-bus, or not. Maybe rotate the log files daily. Exercise left to the reader.
Ah yes, I forgot about that post. I should have responded in that thread to say that I drew conclusions too quickly. At the time when I made that post it was almost two months since I saw the errors last and I assumed it must have been because I reseated the cables. Of course, it wouldn’t be long after that post when the error popped up again.
I have swapped the cable on the one site, but admittedly it was with cable from the same Cat6A roll. However, I’ve been using that same cable for gigabit networking without issue so I have no reason to suspect it.
It seems so. I dread that prospect though, since it is going to be very tedious, given that I have to wait about a month for it to happen. If it turns out to be a faulty battery in each of the stacks I might have to juggle the batteries to identify exacty which one it is, again over the course of months.
This site has US3000C batteries (on the latest firmware). As luck would have it it happens on the site to which I do not readily have access so I can run the CAN bus monitoring as suggested by @plonkster.
Hasn’t happened since my previous post on any of the other sites…
Ok, so I haven’t seen any of these errors on any of the three sites for more than a month since upgrading the Venus OS on their Cerbos to the latest v3 beta.
Has something been changed/fixed in Venus OS, or is this just coincidence?
If you want to find all the old bugs, just put out a beta and tell your users to test it. It doesn’t have to be an actual new beta version, a copy of the old one is fine… they will find ALL the bugs for you
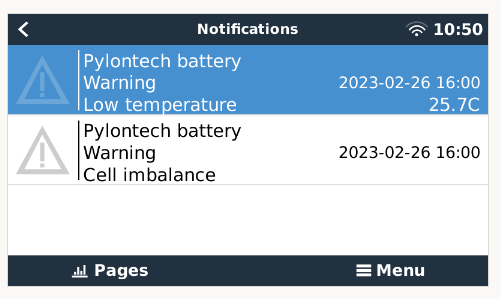
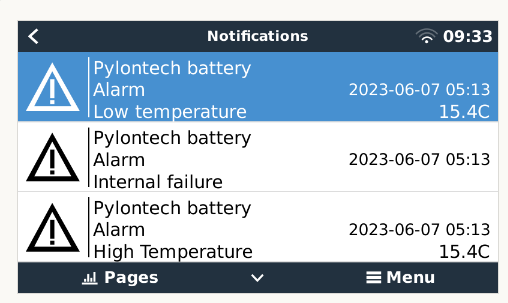
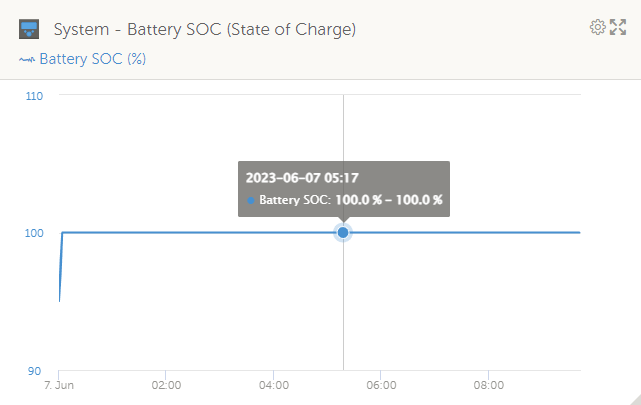
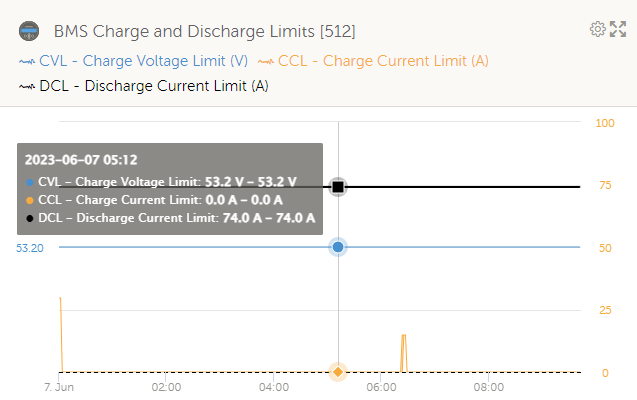
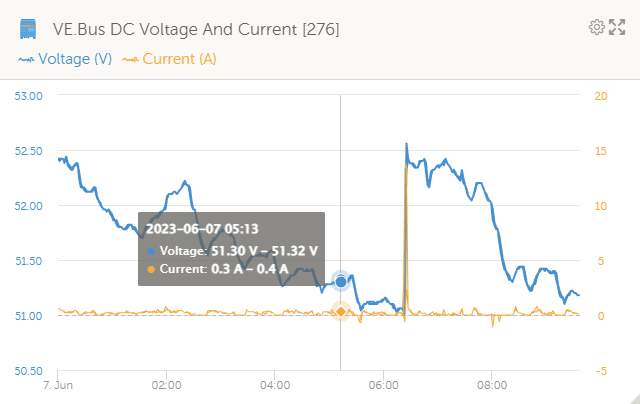
Looks like I got happy too soon. These warnings happened overnight on a remote site, all at the same time:
There was no loadshedding at the time and the batteries were idling at 100% SoC:
Pack voltage was 51.3V:
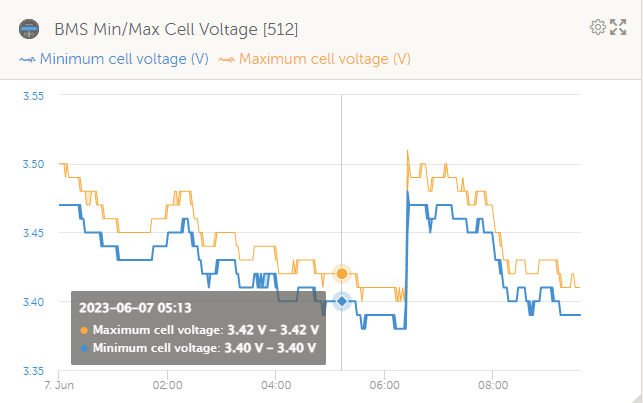
Cell voltages look fine too:
The other sites (which I can monitor more easily) have not thrown any errors recently. I will check the battery event logs when I am on-site again, but from past experience I know these probably aren’t real alarms and there won’t be anything in the logs.
If the battery event logs are indeed empty, then I am inclined to just ignore these. I cannot easily run the CAN-bus monitoring on this site, and it seems to be happening less frequently than once every two months now… so it’s not getting worse.
Hey wait, I’ve seen that type of warning on a non-brand-name bank, when the BMS switched off, with no LS, charged.
Bank fully charged a cell hits 3.65v forcing the BMS to switch off … the resultant weird errors making no sense like High Temp etc.
IF I’m right, a cell went over 3.65v, the Max cell volts graph did not catch it, it ties back to my suspicion that LS levels are not allowing banks to balance properly, the one cycle per day, not enough time to balance the cell over time.
Tedious to fix oneself, using Victron controls under DVCC OR set to Keep Charge, using LS slots to run the bank for more than one cycle per day, week, to discharge/charge, letting the balancer work.
I don’t think the evidence in this case supports this conclusion. The battery bank was idling for several hours and was at 51.3V at the time, so there’s no reason why a cell would blow out to 3.65V.
This site has ESS set to “Keep Batteries Charged”, so it has ample time to keep cells in balance. The minimum and maximum cell voltage graph also does not show any potential issues.
Furthermore, Pylontech batteries usually log all errors, and while I have not yet inpected the battery logs for this event, the last time I checked the logs were empty.
EXACTLY what I saw. Fully charged, ESS set to Keep Charged, yet some watts, in my case, still slipped into the batt, overwhelming the BMS ever so subtly.
Not saying it is the case here, just some experience I had the “pleasure” of not enjoying.
Few other things to check too.
But those warnings you saw on the system, being fully charged no loads … very familiar.
FWIW, when I saw that coming, I used to switch on the oven to create a big drain, so that the inverter can suck some of the charge from the battery.
What happens is we get exactly ONE CAN-bus frame where the high charge voltage and internal error bits are set. The next frame it clears again. Since these frames are sent 3 seconds apart, the alarm literally lasts only 3 seconds.
The bits seems to be around the boundary between two bytes in the 8-byte frame, and personally I think there is a small bug in the Pylontech firmware causing this, but because it is darn near impossible to reproduce, and clearly not a real alarm, the solution was simply to debounce it. Require the alarm to last at least 3 frames or 9 seconds.