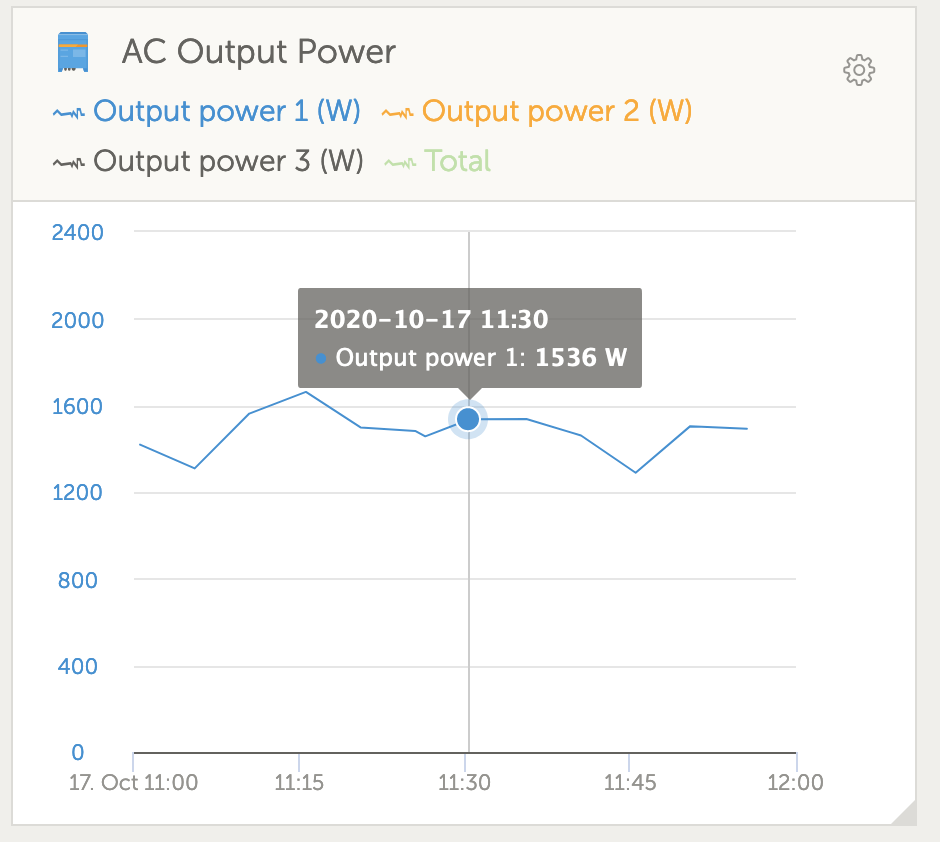
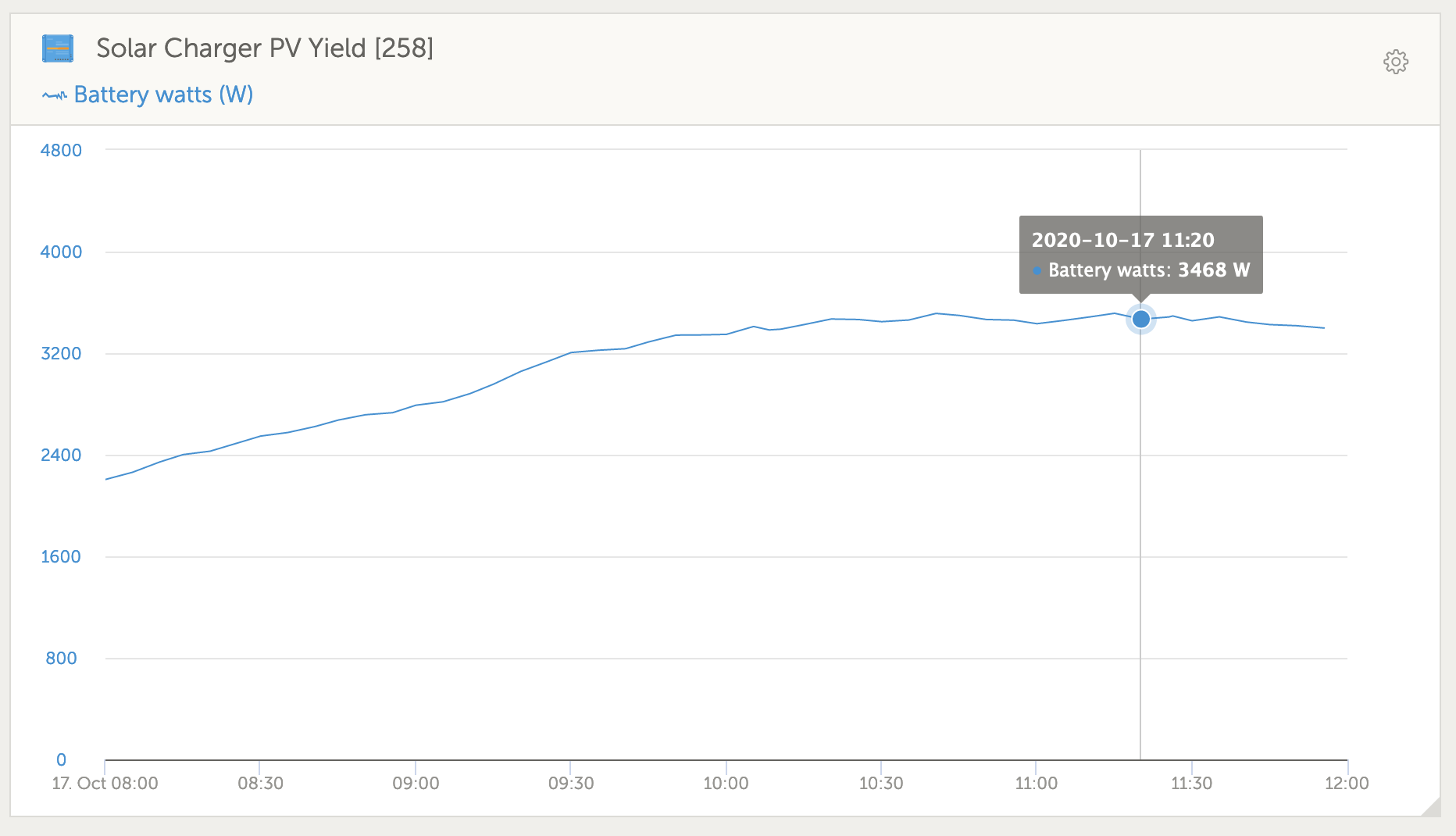
My system has given in last 2 months a few warnings, of inverter overload. But when I check there was no apparent overload from vrm data. I am getting concerned. My inverter is just over one year old.
Just a side note:
I also checked with Victron, my invertor was not on the list of the recalled units of the MPII defected units. Although it has the round bolt and not the square bolt. Apparently the new units have the square bolts.
Should I be concerned, what can I do to debug/find about this error?
This has nothing to do with the electrical load of the inverter
To understand load average, you need a little bit of understanding of how operating systems, multi-tasking and CPUs work. I’ll just dumb it down to this: A computer actually cannot do more than one thing at a time (okay, maybe a few things depending on the number of cores, but it remains limited). So what it does is switch really quickly between task to give the illusion that they are running simultaneously. It is like someone alternating between walking and chewing bubblegum: If he were to alternate really quickly, you would not be able to tell when he is chewing and when he is walking.
So in an OS there will be a number of processes (which is unix speak for programs) that are runable, in other words nothing is blocking them (such as waiting for data to arrive from the disk or some other slow process), the only reason they aren’t running right now is because the CPU is running another process. These runable processes are all in a queue, and the average length of this queue is the load average.
Unix has three of these numbers, which are the averages over 5 minutes, 10 minutes, and 15 minutes. A load average over 5 or 6 is considered extreme. On venus, the watchdog will reboot the device if the load average is too high, ie if the GX device is being overworked.
So this is what hapened, an if it happens only a few times a month, I would not worry about it too much.